当你在 Kubernetes 中部署应用程序时,通常会定义三个组件:
- Deployment — 这是创建应用程序副本的方法。
- Service — 将流量路由到 Pod 的内部负载均衡器。
- Ingress — 流量应如何从集群外部流向您的服务的描述。
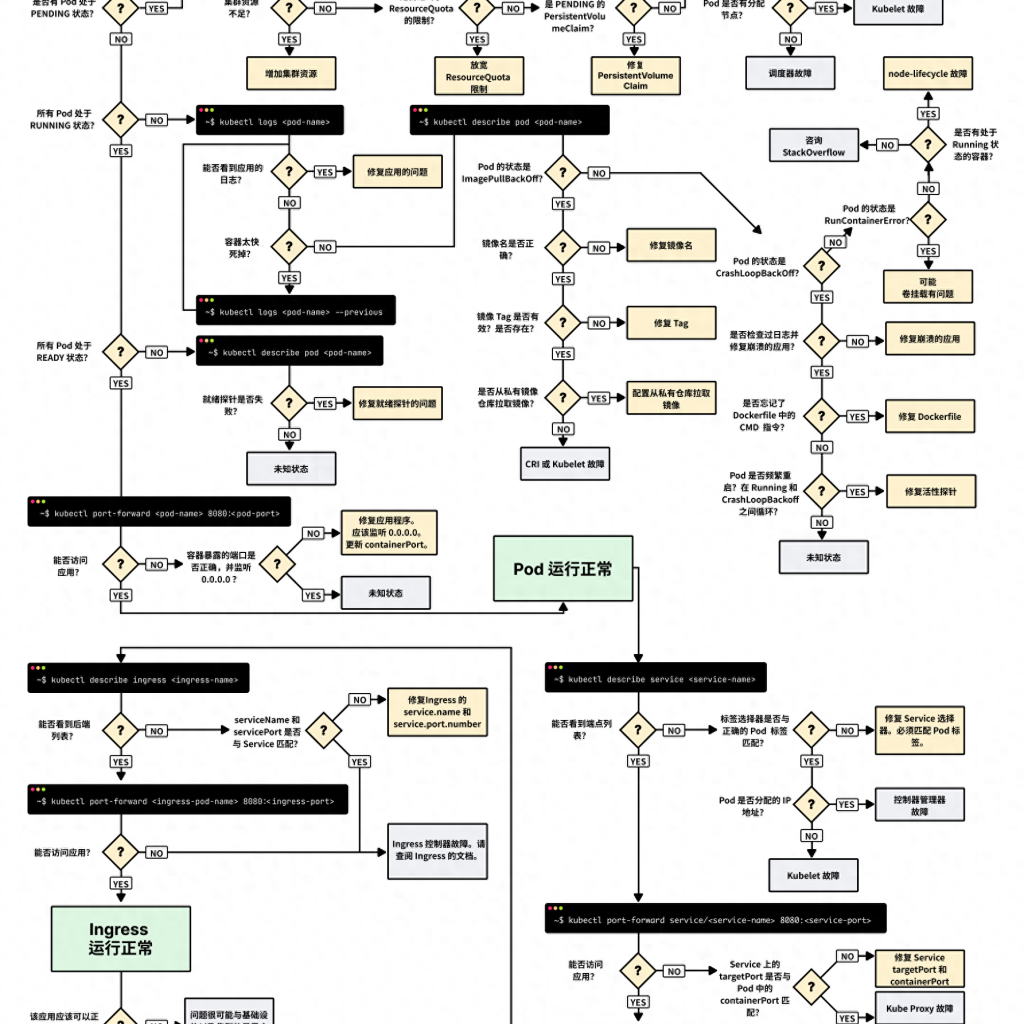
排除 Kubernetes 部署故障的 3 个步骤
在深入调试损坏的部署之前,必须对 Kubernetes 的工作原理有一个明确定义。
由于每个部署中都包含三个组件,因此我们应该从底部开始按顺序调试所有组件。
- 确保 Pod 正在运行;
- 专注于让Service将流量路由到Pod;
- 检查 Ingress 配置是否正确;
1. Pod 故障排除
大多数时候,问题出在 Pod 本身上。
我们应该确保Pod Running且Ready。
如何检查?
kubectl get pods
NAME READY STATUS RESTARTS AGE
app1 0/1 ImagePullBackOff 0 47h
app2 0/1 Error 0 47h
app3-76f9fcd46b-xbv4k 1/1 Running 1 47h在上面的输出中,最后一个 Pod 处于Running且Ready 状态,但是,前两个 Pod 既未Running也未Ready。
如何调查出了什么问题?
有四个有用的命令可用于对 Pod 进行故障排除:
- kubectl logs <pod name> 有助于检索Pod容器的日志。
- kubectl describe pod <pod name> 对于检索与 Pod 关联的事件列表非常有用。
- kubectl get pod <pod name> 对于提取 Kubernetes 中存储的 Pod 的 YAML 定义非常有用。
- kubectl exec -ti <pod name> — bash 对于在 Pod 的容器之内运行交互式命令非常有用。
那我们应该使用哪一个命令呢?
没有一种方法是放之四海而皆准的。
相反,我们应该使用它们的组合。
常见 Pod 错误
Pod 可能会出现启动和运行时错误。
启动错误包括:
- ImagePullBackoff
- ImageInspectError
- ErrImagePull
- ErrImageNeverPull
- RegistryUnavailable
- InvalidImageName
运行时错误包括:
- CrashLoopBackOff
- RunContainerError
- KillContainerError
- VerifyNonRootError
- RunInitContainerError
- CreatePodSandboxError
- ConfigPodSandboxError
- KillPodSandboxError
- SetupNetworkError
- TeardownNetworkError
有些错误比其他错误更常见。
以下是最常见错误的列表以及如何修复这些错误。
ImagePullBackOff
当 Kubernetes 无法检索Pod的image时,会出现此错误。
常见的原因有以下三个:
- image名称无效,例如,拼错了名称,或者image不存在。
- 为image指定了一个不存在的tag。
- 尝试检索的image属于私有镜像仓库,并且 Kubernetes 没有访问凭据。
前两种情况可以通过更正image名称和tag来解决。
最后,应该将私有镜像的凭据添加到Secret,并在Pod中引用它。
CrashLoopBackOff
如果容器无法启动,Kubernetes 会显示 CrashLoopBackOff作为状态。
通常,容器在以下情况下无法启动:
- 应用程序中存在错误,导致其无法启动。
- 容器配置错了。
- K8S LivenessProbe失败次数过多。
这时,我们应该尝试从该容器日志来检查失败的原因。
如果由于容器重新启动太快而看不到日志,可以使用以下命令,它打印前一个容器的错误消息。
kubectl logs <pod-name> --previousRunContainerError
当容器无法启动时会出现该错误。
这甚至是在容器内的应用程序启动之前。
该问题通常是由于配置错误造成的,例如:
- 挂载了不存在的卷,例如 ConfigMap 或 Secrets。
- 将只读卷挂载为读写。
这时,应该用来kubectl describe pod <pod-name>检查和分析错误。
Pod 处于Pending状态
当创建 Pod 时,Pod 处于Pending状态。
假设调度程序组件运行良好,原因如下:
- 集群没有足够的资源(例如 CPU 和内存)来运行 Pod。
- 当前Namespace有一个ResourceQuota对象,创建Pod会使Namespace超出配额。
- Pod 绑定到Pending PersistentVolumeClaim。
最好的选择是通过以下检查命令,查看Pod事件。
kubectl describe pod <pod name>对于由于 ResourceQuotas 创建的错误,还可以使用以下命令检查集群的日志:
kubectl get events --sort-by=.metadata.creationTimestampPod 处于Pending状态
如果 Pod 正在Running但Pending中,则意味着ReadinessProbe失败。
当ReadinessProbe失败时,Pod 不会加到Service,并且不会将任何流量转发到该实例。
失败的ReadinessProbe是特定于应用程序的错误,因此我们应该使用kubectl describe命令检查事件
2. Services故障排查
如果 Pod 正在Running并Ready,但仍然无法收到应用程序的响应,则应该检查Service是否配置正确。
Service旨在根据 Pod 的label将流量路由到 Pod。
因此,我们应该检查的第一件事是该Service映射了多少个 Pod。
可以通过检查Service的Endpoints来执行此操作:
kubectl describe service my-service
Name: my-service
Namespace: default
Selector: app=my-app
IP: 10.100.194.137
Port: <unset> 80/TCP
TargetPort: 8080/TCP
Endpoints: 172.17.0.5:8080Endpoint是一对<ip address:port>,并且应该至少有一个,当服务以(至少)一个 Pod 为目标时。如果Endpoints为空,则有两种解释:
- 没有任何使用正确label运行的 Pod(提示:应该检查是否位于正确的命名空间中)。
- Selector中的Service label配置错误。
如果看到Endpoints列表,但仍然无法访问应用程序,那么Service targetPort可能配置错误。
无论Service type是什么,都可以使用以下方式kubectl port-forward访问到。
kubectl port-forward service/<service-name> 3000:80备注:
- <service-name>是服务的名称。
- 3000是应用程序上监听的端口。
- 80是Service开放的端口。
3. Ingress 故障排查
如果已检查到这部分,那么:
- Pod 正在Running并Ready。
- Service 将流量分配给Pod。
但仍然看不到应用程序的响应。
这意味着 Ingress 很可能配置错误。
由于 Ingress 控制器是集群中的第三方组件,因此根据 Ingress 控制器的类型有不同的调试方式。
但在深入了解 Ingress 检查工具之前,我们可以检查一些简单的内容。
Ingress 使用service.name和service.port访问到服务。
我们应该检查这些配置是否正确,还可以检查 Ingress 是否已正确配置:
kubectl describe ingress my-ingress
Name: my-ingress
Namespace: default
Rules:
Host Path Backends
---- ---- --------
*
/ my-service:80 (<error: endpoints "my-service" not found>)如果Backend列为空,则配置中一定存在错误。
如果可以在Backend列中看到Endpoint,但仍然无法访问应用程序,则问题可能是:
- 我们如何将 Ingress 暴露给互联网。
- 我们如何将集群暴露给互联网。
首先,检查 Ingress 控制器的 Pod(可能位于不同的命名空间中):
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS
kube-system coredns-5644d7b6d9-jn7cq 1/1 Running
kube-system etcd-minikube 1/1 Running
kube-system kube-apiserver-minikube 1/1 Running
kube-system kube-controller-manager-minikube 1/1 Running
kube-system kube-proxy-zvf2h 1/1 Running
kube-system kube-scheduler-minikube 1/1 Running
kube-system nginx-ingress-controller-6fc5bcc 1/1 Running通过describe pod检查端口:
kubectl describe pod nginx-ingress-controller-6fc5bcc
--namespace kube-system \
| grep Ports
Ports: 80/TCP, 443/TCP, 8443/TCP
Host Ports: 80/TCP, 443/TCP, 0/TCP最后,访问到 Pod:
kubectl port-forward nginx-ingress-controller-6fc5bcc 3000:80 --namespace kube-system
Forwarding from 127.0.0.1:3000 -> 80
Forwarding from [::1]:3000 -> 80此时,每次访问计算机上的 3000 端口时,请求都会转发到 Pod 上的 80 端口。
- 如果是这样,问题就出在宿主机上,我们应该检查流量如何路由到集群。
- 如果不起作用,则问题出在 Ingress 控制器中,我们应该调试 Ingress。
如果仍然无法让 Ingress 控制器工作,则应该开始调试它。
Ingress 控制器有许多不同版本。
流行的选项包括 Nginx、HAProxy、Traefik 等。
我们应该查阅 Ingress 控制器的文档以查找故障排查指南。
由于Ingress Nginx是最流行的 Ingress 控制器,因此我们在下面中提供了一些技巧。
调试 Ingress Nginx
Ingress-nginx 项目有一个Kubectl 的官方插件。
您可以用来kubectl ingress-nginx:
- 检查日志、后端、证书等。
- 访问到 Ingress。
- 检查当前配置。
我们应该尝试的三个命令是:
- kubectl ingress-nginx lint,检查nginx.conf.
- kubectl ingress-nginx backend,检查后端(类似于kubectl describe ingress <ingress-name>)。
- kubectl ingress-nginx logs,检查日志。
请注意,您可能需要使用 为 Ingress 控制器指定正确的命名空间–namespace <name>。
故障排查总结
如果我们不知道从哪里开始,在 Kubernetes 中进行故障排除可能是一项艰巨的任务。
我们应该始终记住自下而上地解决问题:从 Pod 开始,然后通过 Service 和 Ingress 向上排查。
在本文中学到的相同调试技术可以应用于其他对象,例如:
- 异常的Jobs 和 CronJobs。
- StatefulSet 和 DaemonSet。
来源:https://www.toutiao.com/article/7266008092235104827/
另,如有需要,请添加wx咨询。wx:oneaicat
